We propose BenchLMM to investigate the cross-style capability of Large Multimodal Models (LMMs). This includes their proficiency in tasks like analyzing images with diverse styles, processing images acquired from non-RGB cameras, and interpreting images sourced from specific application knowledge. In this section, we will elaborate on how we build the benchmark that encompasses these diverse styles.
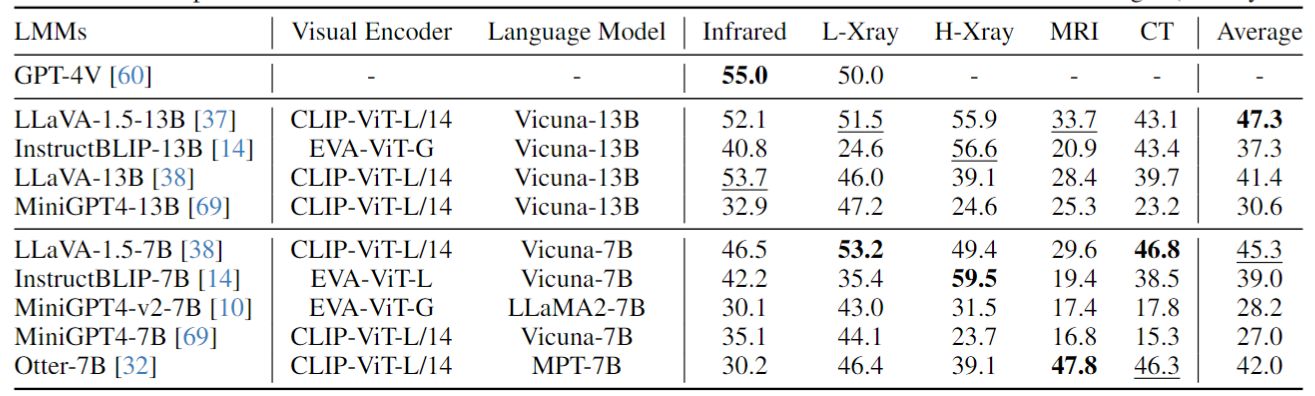
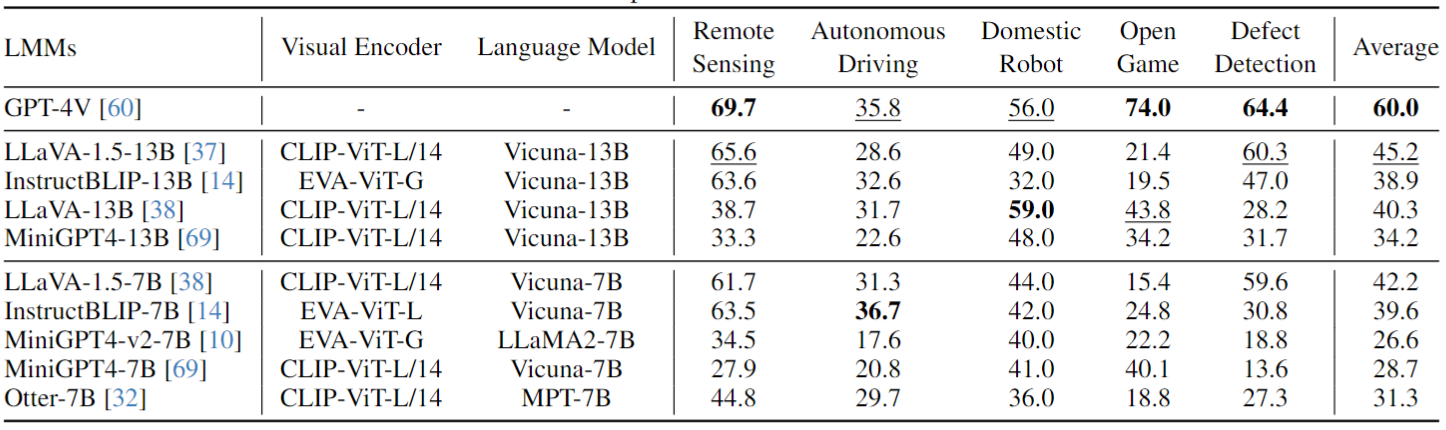
In most existing works, LMMs are predominantly evaluated using images in the 'Photo' style, leading to a gap in understanding their performance across diverse artistic styles. We extend the evaluation scope by examining LMMs' performance with various artistic styles beyond the common 'Photo' style. Results, as detailed in Table, reveal a notable decline in LMMs' effectiveness when processing these artistic styles. This trend suggests a potential overfitting of LMMs to the 'Photo' style, highlighting their limited adaptability to varied artistic styles, a capability that humans typically possess. Interestingly, GPT-4V, despite being a robust commercial model, exhibits similar limitations in handling diverse styles.




@misc{cai2023benchlmm,
title={BenchLMM: Benchmarking Cross-style Visual Capability of Large Multimodal Models},
author={Rizhao Cai and Zirui Song and Dayan Guan and Zhenhao Chen and Xing Luo and Chenyu Yi and Alex Kot},
year={2023},
eprint={2312.02896},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
This research is supported in part by the Rapid-Rich Object Search (ROSE) Lab of Nanyang Technological University and the NTU-PKU Joint Research Institute (a collaboration between NTU and Peking University that is sponsored by a donation from the Ng Teng Fong Charitable Foundation). We are deeply grateful to Yaohang Li from the University of Technology Sydney for his invaluable assistance in conducting the experiments, and to Jingpu Yang, Helin Wang, Zihui Cui, Yushan Jiang, Fengxian Ji, and Yuxiao Hang from NLULab@NEUQ (Northeastern University at Qinhuangdao, China) for their meticulous efforts in annotating the dataset. We also would like to thank Prof. Miao Fang (PI of NLULab@NEUQ) for his supervision and insightful suggestion during discussion on this project. This website is adapted from Nerfies, licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
